VidSitu
Towards understanding situations in videos
Towards understanding situations in videos
VidSitu is a large-scale dataset containing diverse 10-second videos from movies depicting complex situations (a collection of related events). Events in the video are richly annotated at 2-second intervals with verbs, semantic-roles, entity co-references, and event relations.

Annotations in VidSitu support the Video Semantic Role Labeling (VidSRL) task which consists of 3 subtasks.
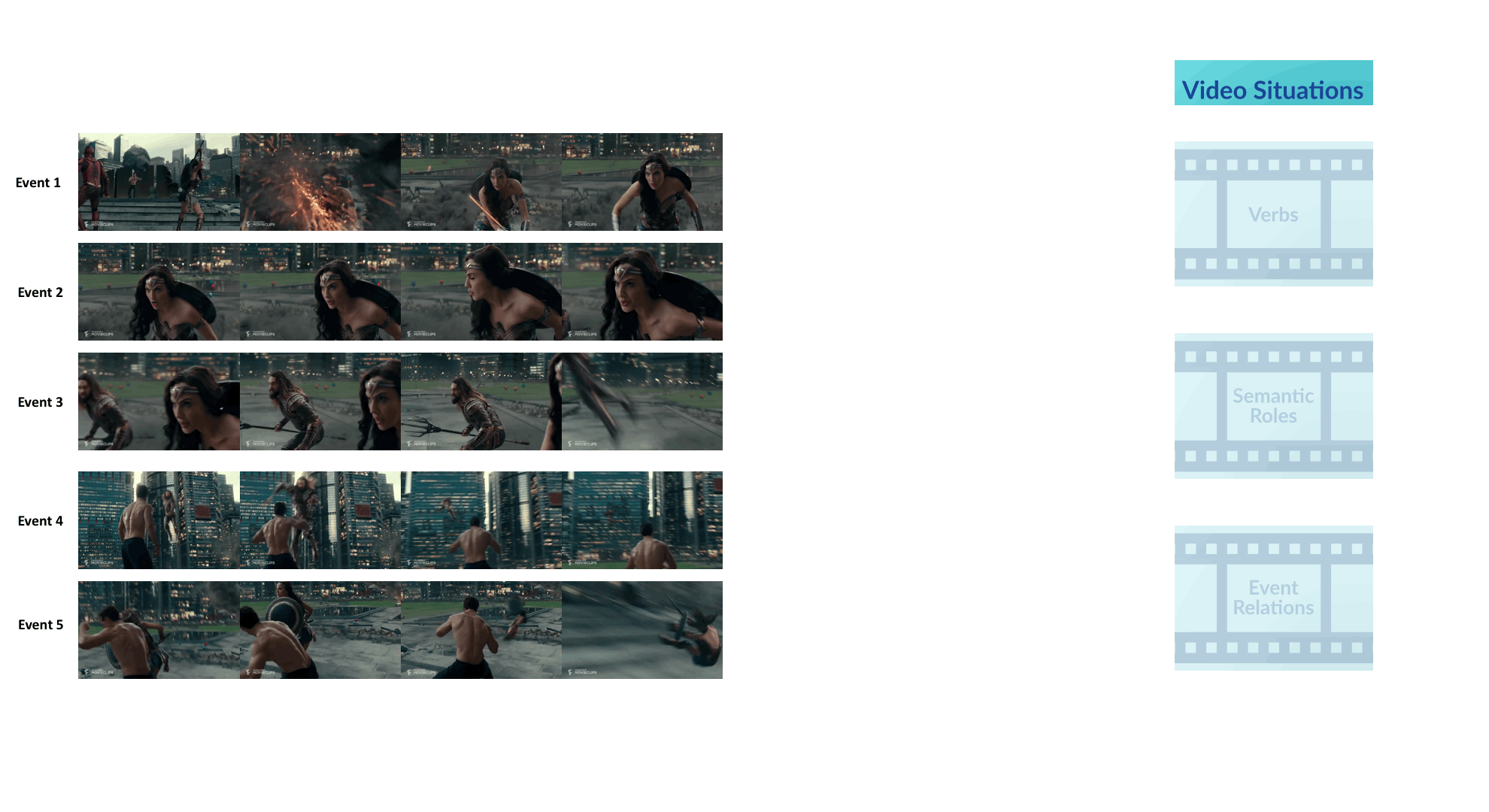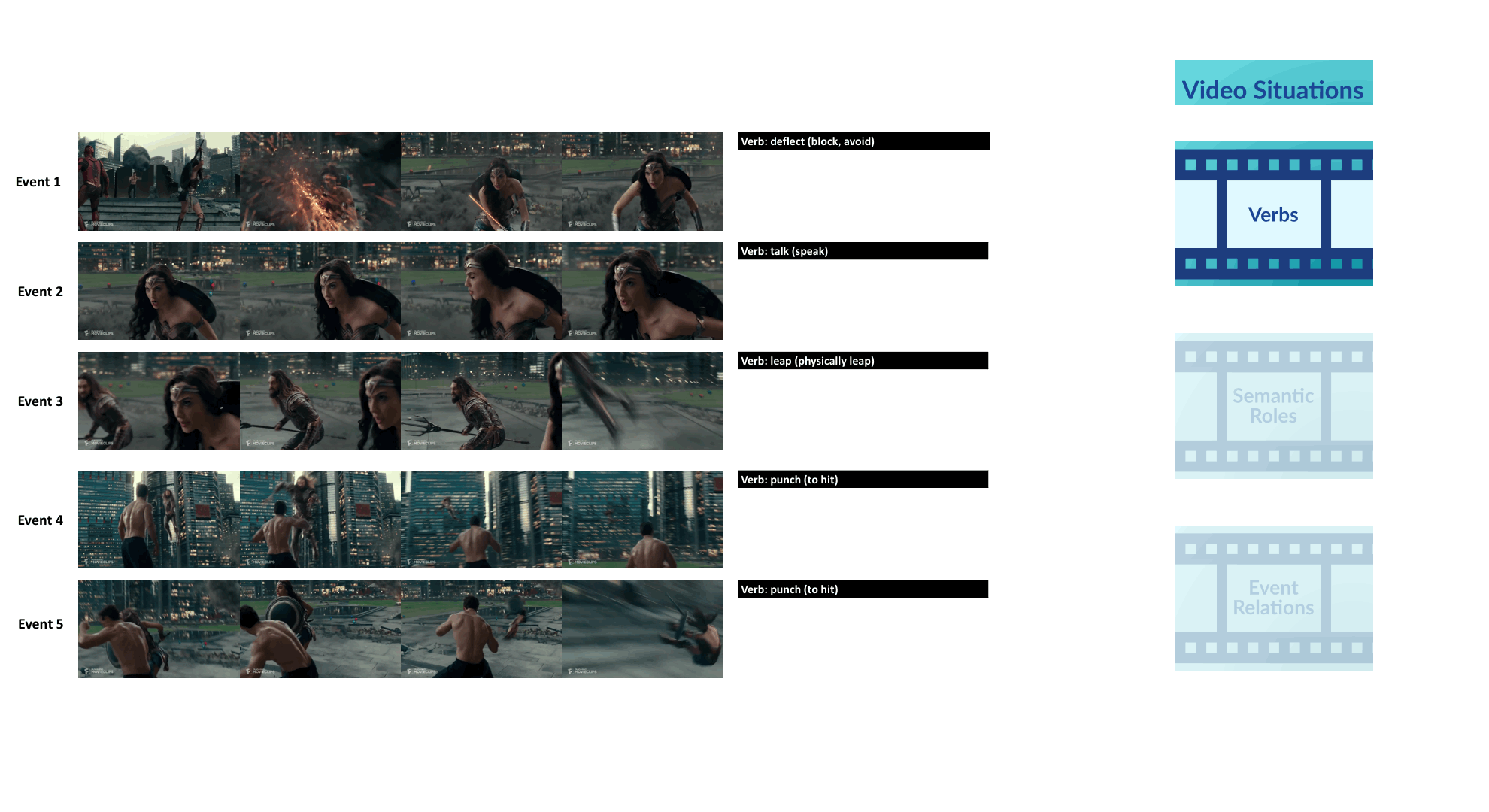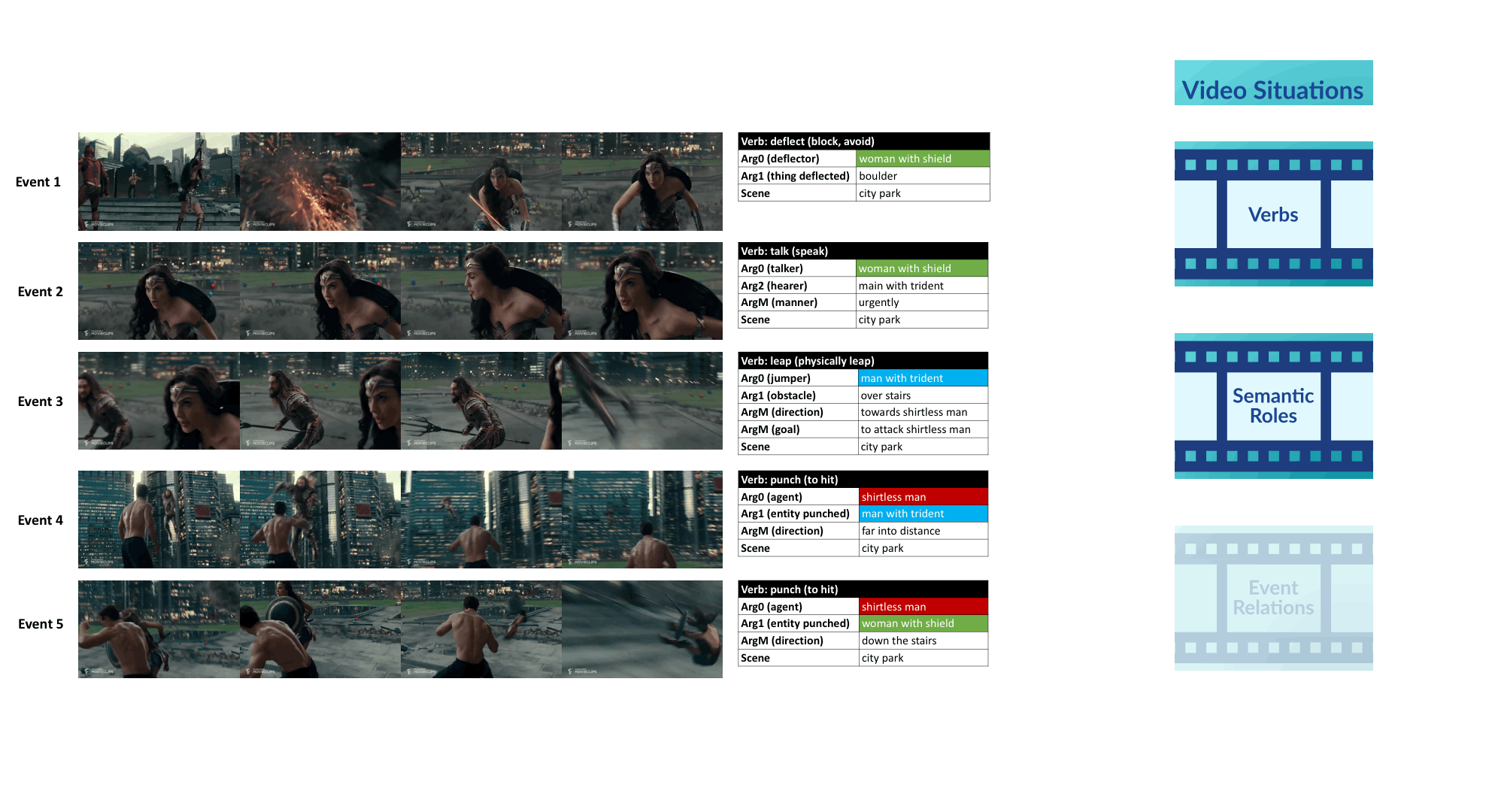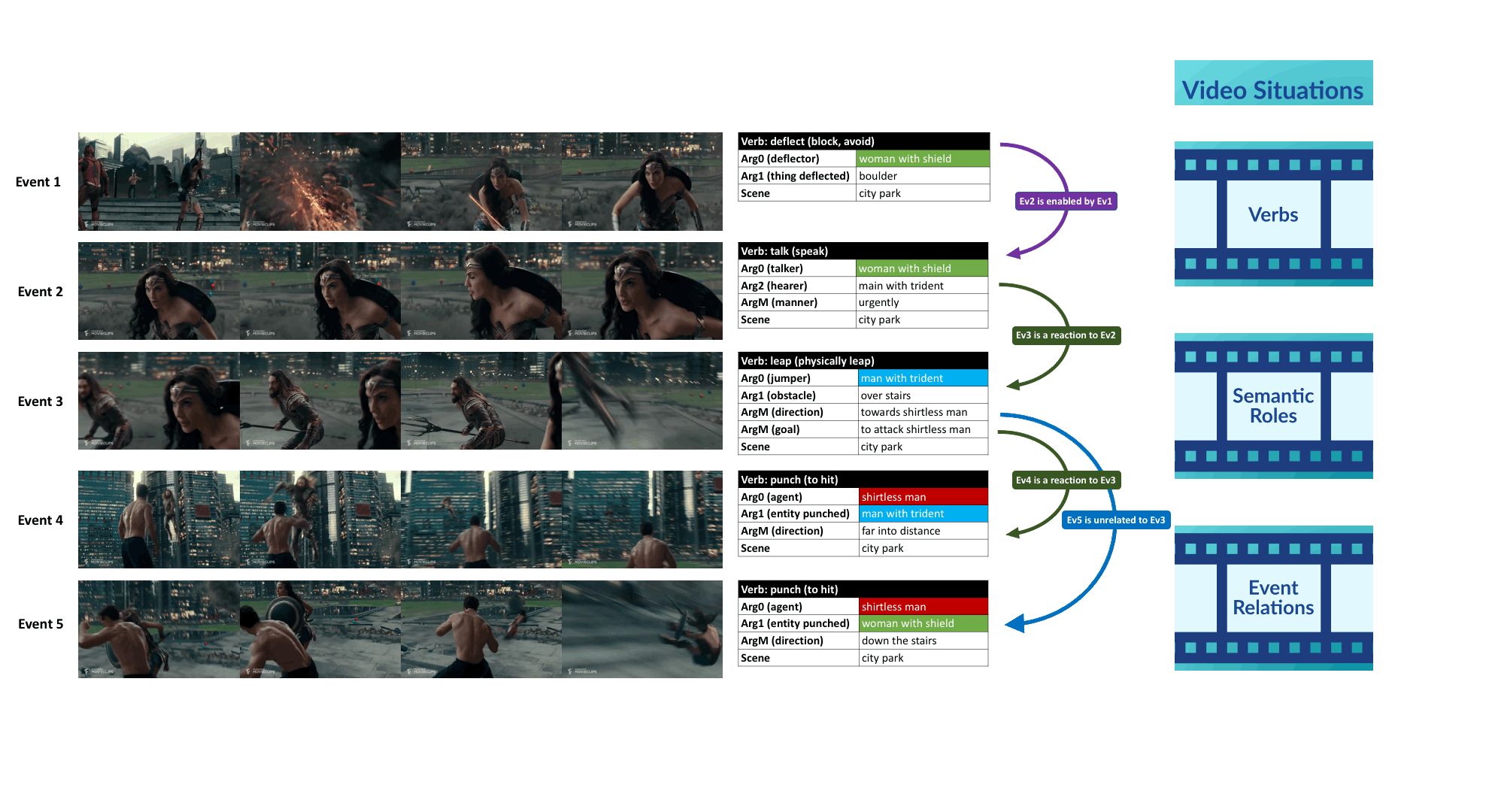

If you find our work helpful, please cite the following paper:
@InProceedings{Sadhu_2021_CVPR,
author = {Sadhu, Arka and Gupta, Tanmay and Yatskar, Mark and Nevatia, Ram and Kembhavi, Aniruddha},
title = {Visual Semantic Role Labeling for Video Understanding},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021}}
Detailed instructions for downloading VidSitu are provided on the accompanying Github repo. This repo provides:
Please reach out to Arka Sadhu (asadhu@usc.edu) for any queries.