Video Semantic Role Labeling Challenge
Part of the ActivityNet Challenges
CVPR 2021
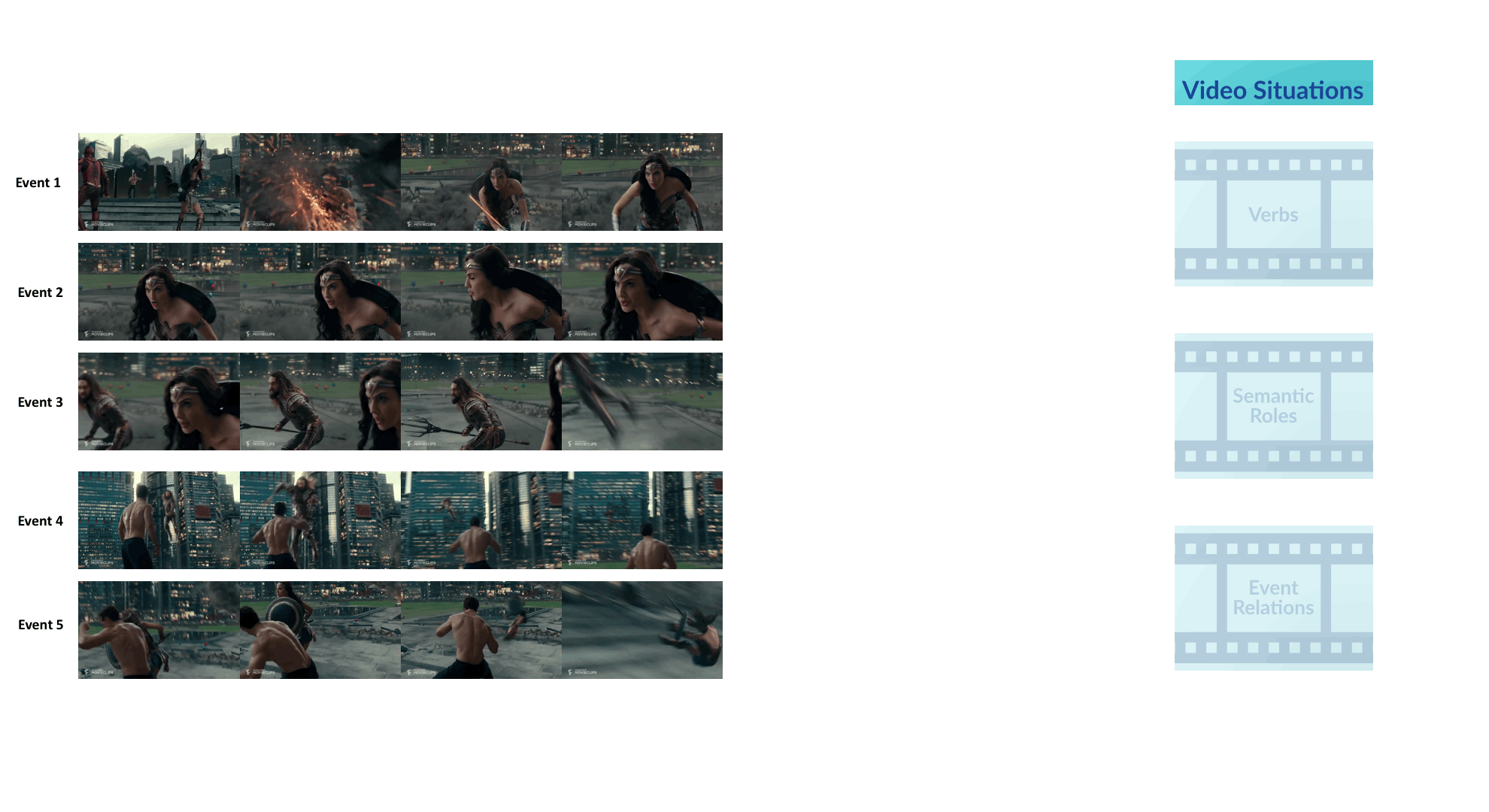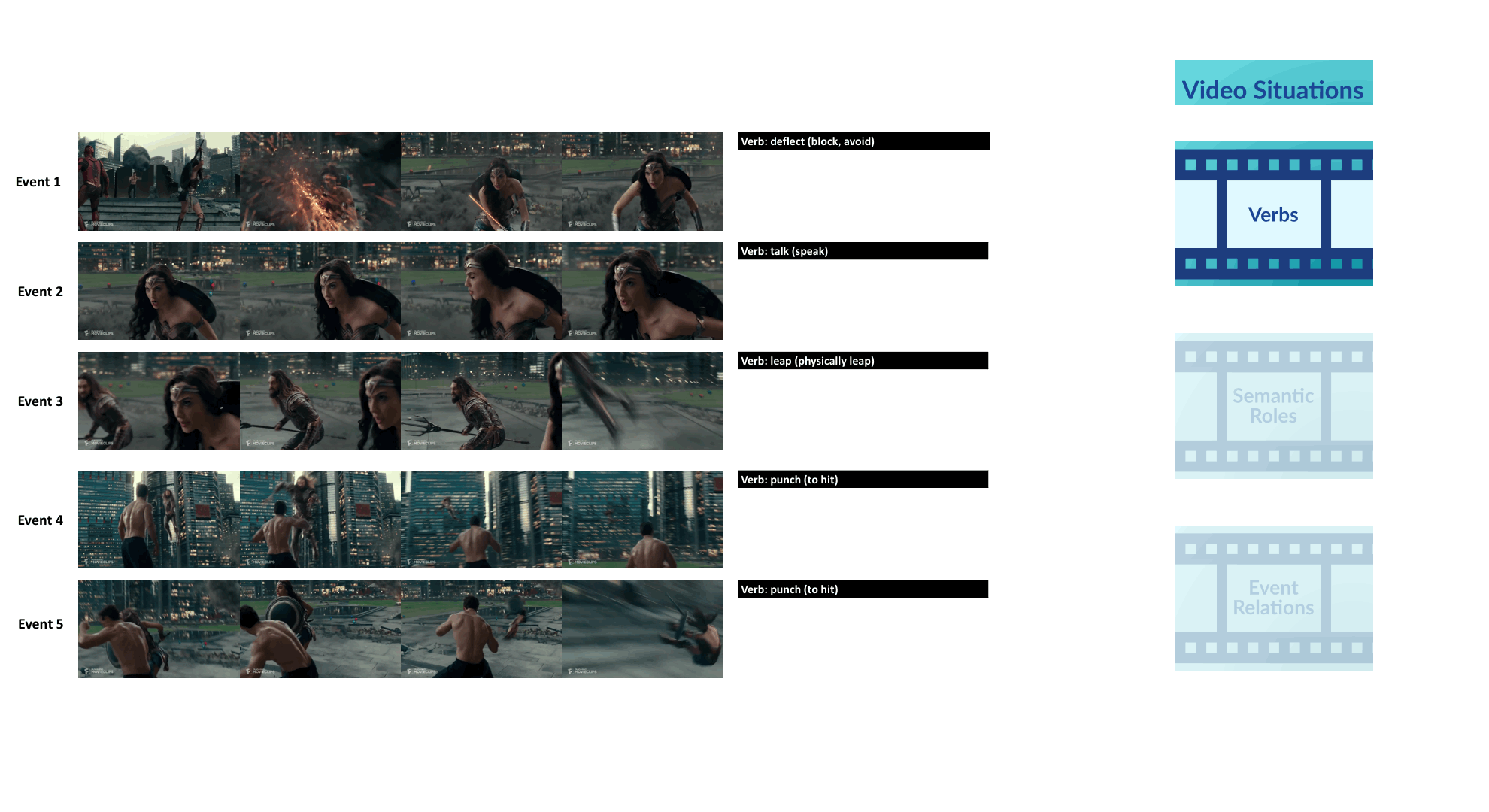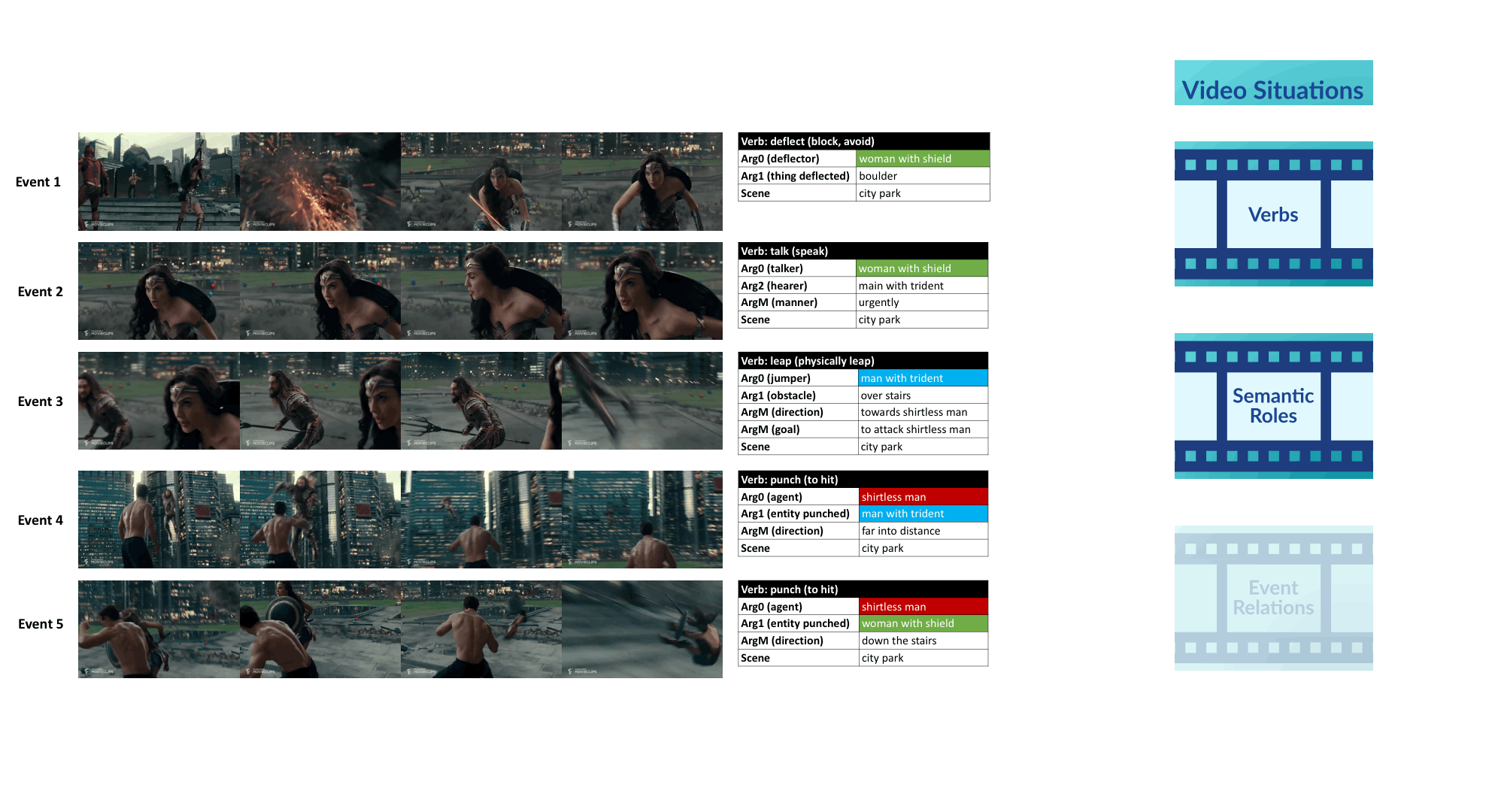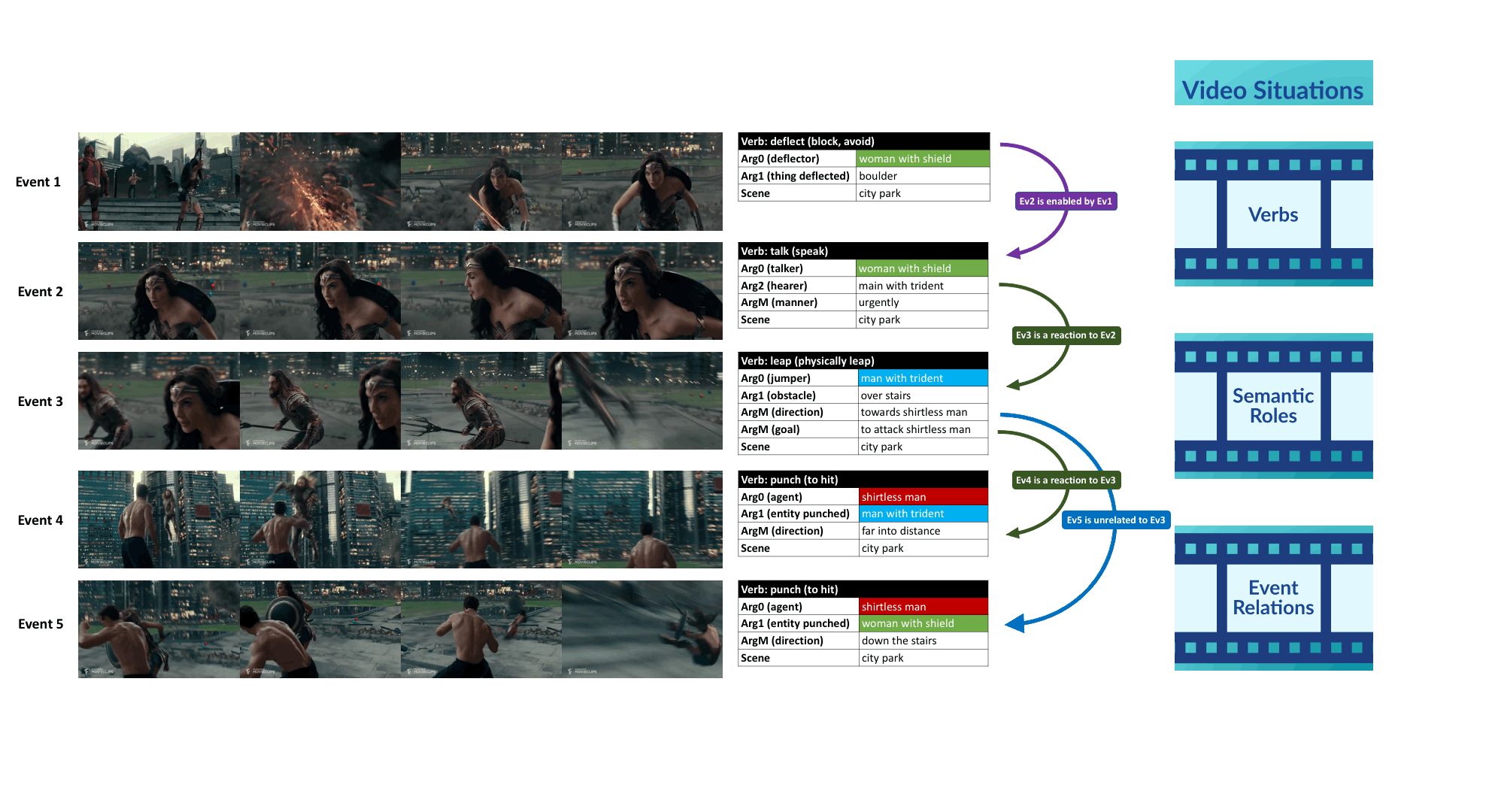
Videos often depict complex real-life situations. While the vision community continues to make progress on building blocks like activity recognition, temporal localization, and tracking, the goal of this challenge is to strive for more complete video understanding than can be afforded by action labels and object detection only. Specifically, this challenge evaluates the ability of vision algorithms to understand complex related events in a video. Each event may be described by a verb corresponding to the most salient action in a video segment and its semantic roles. VidSRL involves 3 sub-tasks: (1) predicting a verb-sense describing the most salient action; (2) predicting the semantic roles for a given verb; and (3) predicting event relations given the verbs and semantic roles for two events.
While producing accurate and descriptive captions for videos would be a remarkable display of algorithmic video understanding, VidSRL provides a more complete and structured representation of related events, and a more thorough three-part evaluation.
The challenge is based on the VidSitu dataset which consists of over 80 hours of richly annotated movie-clips. VidSitu has 29.2K 10-second videos annotated with events every 2 seconds. We refer to each 2 second segment as a clip. The train, validation and test splits are desribed below. Note that the train and validation annotations are available for download where as the test annotations are only available through the online evaluation server.
| Split | Description |
|---|---|
| Train | 23626 videos with each of the five 2-second clips within a video is annotated with a verb and corresponding semantic roles |
| Validation | 1326 videos annotated similar to the train set |
| Test-Vb | 1353 videos for evaluating verb-sense prediction. Each clip is annotated with 3 verbs to account for variability in selection of the salient activity |
| Test-SRL | 1598 videos for evaluating semantic role prediction for a chosen verb. Each clip is annotated with 3 sets of semantic roles for the same verb to account for variability in referring expressions. |
| Test-ER | 1317 videos for evaluating event-relation prediction. Each clip is annotated with relation to the central event (the 4-6 second clip). We provide 3 annotations to handle relation ambiguity. |
The VidSRL evaluation has three parts, each with its own leaderboard. For the purpose of the callenge, we will announce winners for each leaderboard. Each leaderboard requires submitting a single .pkl file of predictions for the corresponding test split. Detailed submission instructions, including prediction formats required for evaluation, are available on the respective leaderboards. Below, video refers to a 10-second video segment which consists of the 5 non-overlapping 2-second clips and the central clip refers to the segment spanning the 4-6 second interval within the video.
| Leaderboard | Input | Output | Test Split |
|---|---|---|---|

|
Video | Verb-sense per clip | Test-Vb |

|
Video and verbs for each clip | Semantic roles per clip | Test-SRL |

|
Video, verbs, and semantic roles for each clip | Relation of each clip to the central clip | Test-ER |
| When | What |
|---|---|
| April 5 | Evaluation servers and leaderboards online |
| June 4 | Submission deadline for challenge purposes |
| June 19-25 | Winners announced during the ActivityNet Workshop @ CVPR 2021 |
Please reach out to Arka Sadhu (asadhu@usc.edu) for any queries.